
如何搭建一个高效的Scrapy爬虫系统
说到用Scrapy搭建爬虫系统,咱们得先搞明白几步关键操作,别着急,这里帮你理个清楚:
-
创建Scrapy项目:打开命令行,输入
scrapy startproject myproject,这样一来,项目目录结构就自动生成啦,里面涵盖了爬虫、管道等模块,真心方便。 -
开发爬虫程序:在
spiders目录下建个爬虫文件,比如myspider.py,让它继承scrapy.Spider类,然后定义爬虫名字name,接着写你的抓取逻辑。 -
配置下载器中间件:这里就比较关键啦,可以启用
HttpProxyMiddleware和RetryMiddleware这些中间件,帮你处理代理和请求重试的逻辑,确保爬虫更加稳定高效。
整套流程下来,Scrapy的强大就展现出来了,你会发现它自动管理请求,支持多线程,非常适合搞大规模数据抓取,简直是爬虫界的超级英雄!
网络爬虫有哪些实用的软件可以推荐
说了搭爬虫,肯定想知道市面上有没有好用的工具吧?嘿嘿,瞧瞧这些大热推荐,绝对能帮你轻松采集数据,放心使用:
-
八爪鱼
- 海外版超牛的爬虫软件!
- 有免费和付费版本,付费还能享受云服务。
- 独家优势:完全可视化操作,没技术门槛!还能自由设置Xpath,支持导出多格式的数据。
- 还有广告封锁,保证采集过程更干净! -
ParseHub
- 又一款免编码的神工具!
- 免费版功能已经杠杠的,适合抓取复杂结构的数据。
- 支持桌面操作,界面简单,快狠准! -
Selenium
- 不仅是测试利器,也能爬数据,超灵活!
- 它能模拟真实用户操作,尤其适合动态加载的网页。
- 如果你遇到JS渲染网页,玩这个完全没压力。
这些软件真的非常适合小伙伴们,不论你是技术小白还是老司机,都能找到合适的利器,轻松搞定各种数据采集需求。
相关问题解答
-
Scrapy项目应该怎么快速入门呢?
哎呀,这个超简单!先用scrapy startproject命令生成项目,接着在spiders目录下写爬虫,别忘了配置中间件,它们帮你自动管好代理和重试。跟着写几波请求,调试几次,马上就上手啦,根本不难! -
八爪鱼和ParseHub哪个好用?
哎呦,这俩都挺棒!八爪鱼更适合想要云服务和完整生态的用户,界面也超友好;ParseHub偏向免编码,操作简单,如果你不想动代码,选它妥妥的。具体看你需求啦,反正都能帮你省心采集。 -
用Selenium爬动态网页真的很有效吗?
真的超级棒!因为它能模仿真实浏览器用户,哪个按钮点哪个,页面JS都能完全加载完,简直是抓取复杂网页的秘密武器。只是运行稍慢一点,适合有点耐心的同学。 -
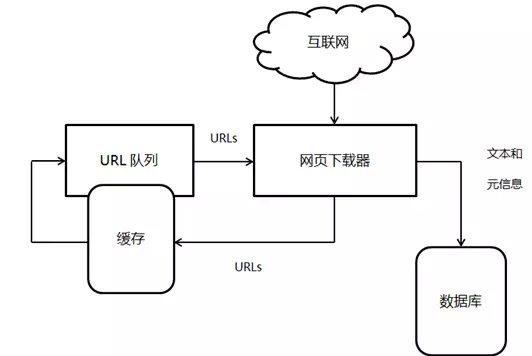
下载器中间件到底有什么用,怎么配置?
这个问题问得好!简单说,下载器中间件就像爬虫的“保镖”,帮你处理请求里的各种小插曲,比如自动切换代理、防止被封、请求失败自动重试等等。配置时只要在settings.py里启用HttpProxyMiddleware、RetryMiddleware啥的,一切自动搞定,省心又省力。







新增评论